
Deconstructing bubble machine
Deep dive into math and business logic behind X current recommendation system and its replacement - The Phoenix


We shape our tools and thereafter our tools shape us!
- John Culkin
You can follow interactive version of this article here - https://ernests.github.io/the-algorithm/index.html
I'm quite avid social network user. I was there when Web 2.0 was born and all sorts of web apps appeared. It was fun to test each of them. Kind of the same way how Web 1.0 was about going “on line” to check some new “web sites”. Now it happens again with all sorts of AI tools. But that’s for another time.
If Web 1.0 was about information, than Web 2.0 was about people. Connecting them, sharing information, learning, co-creating. Now anyone could have a place online and create content. Create, share, repeat. Delicious for sites, Digg for new things (overtaken by Reddit), Foursquare for places, Flickr for photos, Twitter for news, Facebook for friends, Linkedin for colleagues. Everything what Web 1.0 was but with people. Like now we have everything but with AI. If you want to go down the memory lane, this song is for you:
No AI, pure creativity!
Fun times. Some survived, some died, some evolved. But one particular aspect changed dramatically. Social networks converged towards this one UI/UX pattern - The Feed. One interface to rule them all - an endless timeline of content.
At first it was about our friends (whatever “friend” is on particular platform) and what they do. Than it was about our friends and some random shit. And than it became random shit and some of our friends.
What happened, why it is this way? How it works? No one knows but everyone has a feeling that there is something off and probably not good for health, society and overall human wellbeing.
And here comes Elon.
Great!
Long story short, Elon bought Twitter, renamed it to X (as everything he touches) and open sourced it’s recommendation algorithm.
This repo titled “the-algorithm” has been pretty dormant until this September (the year 2025).
I'm always been interested in algorithms and how they work. I have built (and building) my own systems to analyse and connect people with help of math. Naturally I'm curious about what’s under the hood.
Analysing such large systems is not easy. Literally, those are tens of thousands lines of code. It’s like going into unknown forest and hoping that you will find your way back.
The original motives were noble - here you go kids, analyse the code and tell us how to improve it. In reality only ones who could actually understand how it works, probably, were some nation level actors with deep interest in how to manipulate such systems. Just sayin’!
Thankfully now we have AI which can help us to peak under the hood. I was curious to see how Claude code can handle this code exploration task. “We” took notes and created interactive representations to ilustrate main concepts. Notes themselves are quite a mess (will do it differently next time) so I have left them out. But the rest I have published on github and have also added references to relevant pieces of content.
This is X recommendation system but it’s building blocks and general ideas can be felt across all other feed based systems. I thought that I already knew how it probably works but to my surprise I learned a lot.
So let’s jump in.
Clusters
Without much of hesitation, let’s don’t beat around the bush and cut it to the chase. At the core of the algorithm are clusters of interest. A lot of them. Around 145000 to be exact.
Ok, why this amount and how they are determined?
Here is the recipe how to make it yourself:
Take top 20m most popular accounts (X calls them Producers).
Analyse their followers and create a matrix of how many unique followers they each share. Result should be beautiful representation of shared follower map.
Now that we have this representation, we can apply Sparse Binary Matrix Factorization (SBF) with Metropolis-Hastings optimization (Welcome to captivating world of sparse optimization). Through educated guess, trial and error we come to conclude that right amount of clusters might be 145000 and so it is. This nice piece of math creates clusters.
And finally for each of Producers assign single cluster they are mostly relevant to.
This analysis in context of X recommendation algorithm is called KnownFor. Now we have created 145000 “communities”. According to old blog post (by the way, this is the last post from engineering team and nothing since 2023), these communities are recalculated every three weeks.
At any given time you can be part of up to 50 of them and you will “drop out” of cluster if your affiliation will be below a threshold.

Your initial clusters are “assigned” when you sign up and pick first accounts you would follow. These are your temporal cluster assignments. Your launchpad. From now on your preferences will be updated on a weekly basis. Each week algorithm readjusts your preferences based on your weekly engagement.

Yeaaaah, about that! Clusters are determined by engagement.
Engagement is the king
Ok, what is an engagement? Lets say there is a tweet. Your actions in context of this particular tweet are engagement metrics. Overall there are 9 of them. All interactions create a sum of the points which become your preference.
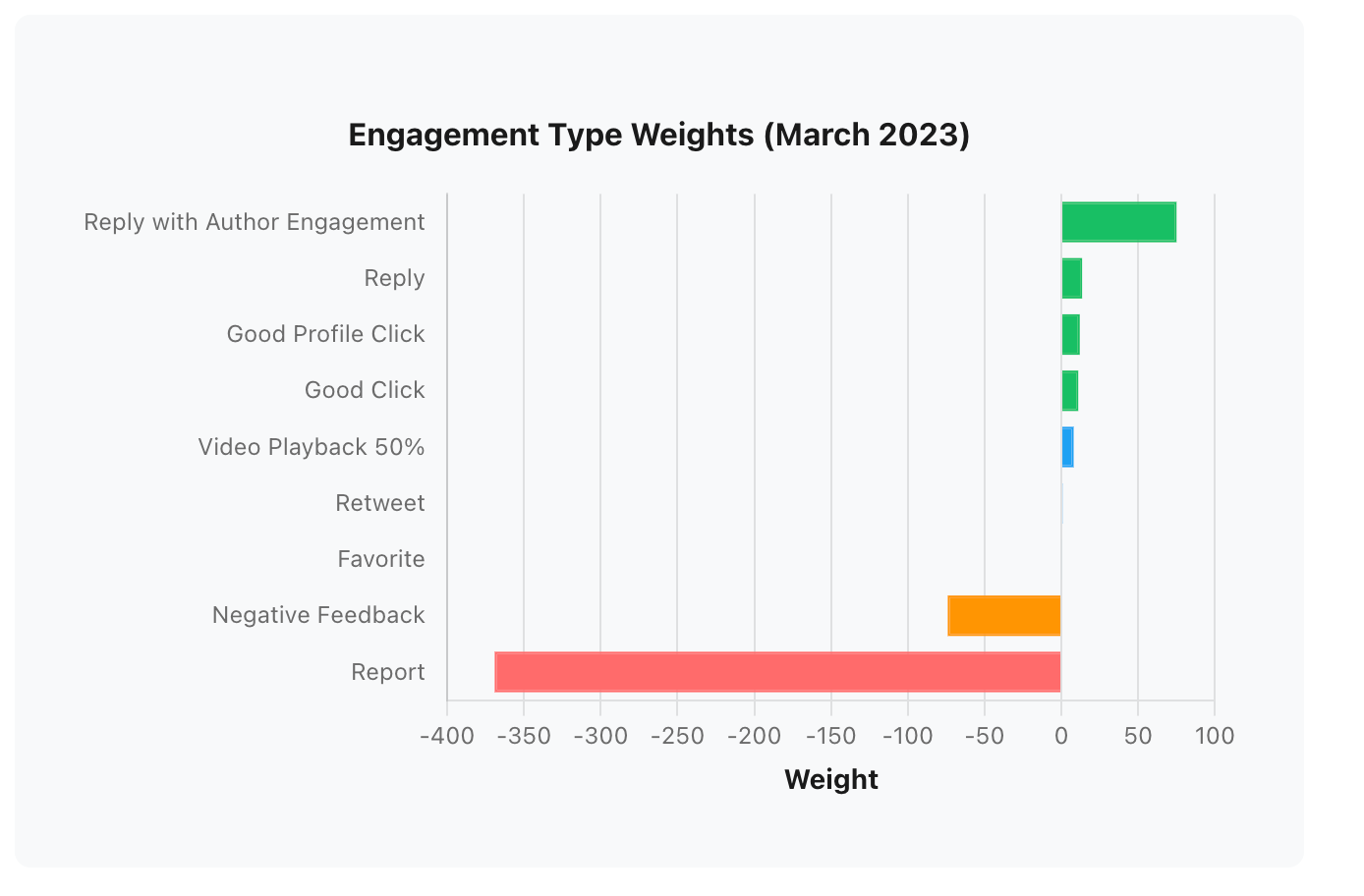
Actual weights are not present in this particular repo but there is a shapshot in another repo - the-algorithm-ml - indicating what weights have been as of March of 2023 and thus I use them to illustrate intuition and dynamic behind engagement.
Green are positive weights and red are negative weights. As you can see, Retweet and Favorite (likes) have very little value or nearly no value at all - 0.5 points. Looking at persons profile and looking at conversation are positive signals - 12.0 and 13.5 points. Reply has a big impact. But getting engagement back from author of the tweet is whopping 75.0 points. You would have to like 150 tweets to have the same impact as single reply from author.
The counter weight are “Don't show me this” and Report. Those have huge negative impact. BUT they are user level, meaning you won't see content from this particular person but it won't affect content itself and for other people similar to you, it will be shown.
Content is just an object in X universe. In itself it has no value or effect on what you see. The value comes from engagement with the object - tweet. Engagement is like gravity in this universe. The more you engage, the more likely you are being pulled in direction of such content. Not based on meaning but based on your likely hood to engage.
I somehow thought that there will be at least some content dimension but there is none (as of now). Pure engagement prediction.
People are having fun about “Reply guy”. But from X universe physics perspective, “reply guy” is just pulling himself closer to whatever cluster his engagement target belongs to.
I have two separate accounts and thus can see how this plays out in practice.
Some engagement is positive. One of my accounts is in AI, DSPy, philosophy bubbles. The more I engage, the more I get similar content in following week. One week it is philosophy, another it is DSPy. People exchanging ideas, opinions and overall it is positive experience.
I'm also part of Latvian cluster which basically is raging fights between right wing and leftists. Same people, new week, new content to disagree on.
KnownFor, InterestedIn and Producers
We already got to know KnownFor analysis which forms the clusters. These are initial clusters/communities of top 20m most popular people on X. This is recalculated every three weeks.
InterestedIn. This is your consumer profile. As you may guessed if KnownFor is about what people create and are “known for”, this is what you are “interested in”. Or to be precise - what content you may be interested to engage with.
This is recalculated every 7 days. So every 7 days you may see a drift in your timeline based on what you have engaged with in past week. But here is the catch. Your old interactions are also taken into account and has value.
Engagement from 3 months ago still carries 50% weight/importance, 6 months ago still 25%. Old engagement lingers for months, making your cluster scores slow to shift.
In practical terms this means if you have engaged a lot with some people back and forth for a week, this will have strong impact on what is recommended for you for several month to come.
Producers. This is your producer profile and is recalculated by Producer Embeddings. It determines whom to show your content.
Consumer InterestedIn calculates what kind of content to show you. It has one-from-many relationships.
Producer Embeddings works in opposite way - many-to-one. Based on who engages with you, whom to expose your content.
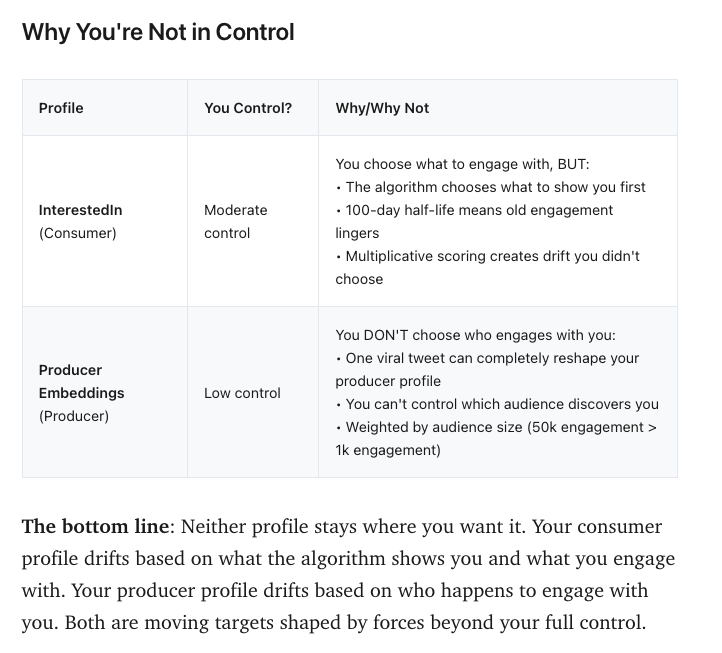
These both profiles can have different path. You may have Consumer profile which is totally different from your Producer profile. For example you are interested in Cooking but write about AI and have totally different bubble consuming your content.
Neither of these profiles are in user control and there is no transparency why it works this way.
One more thing, in Producer embeddings only accounts with more than 100 followers are included. Below that threshold you have no algorithmic boost with exposure. When you have 101 followers your content is being calculated and shown to users to understand if they will engage with your content. Takeaway, get 100 followers.
Algorithmic aristocracy
Not every one is equal. Some are more equal than others.
There are several forces which “naturally” create an algorithmic aristocracy where big accounts get more exposure than smaller accounts.

Verified badge. With Verified badge (8$) you get boost to your reach. Based on algorithm it seems to be 100x.
If your content gets more than 16 engagements, it gets additional boost. Small accounts “have no friends”, “have no likes”, “have no boost”.
Following/Follower ratio. If you are following more than 500 people, algorithm will check what is the ratio. And it is harsh. If you are following 500 accounts and only 100 people follow you, this will have huge negative impact on your content reach. Large accounts don't have this problem.
Out-of-Network Penalty. How many people can see your content out of your network. If you have small follower base, you can reach additionally 75% out of your network. For 100 follower account those would be additionally 75. For account with 1000 followers those would be additional 750. Big difference.
As you can see, those are multiplying and as a result account with large following and Verified badge, has different treatment where smaller accounts have to fight for it.
The loop
Now, lets see how it all plays out together.
It’s simple. Think of engagement as gravity. Whatever you or anyone else does, creates gravity .
You start by having your list of accounts you follow. You engage with some content. This engagement rearrange your cluster preference and now you will have more of what you engaged with. As you see more of what you engage with, probably you will engage even more. You are now in the orbit of this topic/cluster.
The sad part is that once you are pulled into clusters and settled, it is hard to leave. Engagement gravity always tries to find perfect match and you will gravitate towards couple of communities. It’s nearly impossible to leave bubbles because your engagement past still haunts you. You can unfollow all people you follow and you still will be in the bubble. You can mark that you are not interested in certain content. This will remove the account but won’t affect your overall profile and bubble affiliation. You are stuck.
This physics also opens ground for manipulation.
One of the most simple manipulations is introduction of controversy. Claiming something about “the other side” that triggers engagement. “All democrats/republicans are idiots because of x, y, z”. If this is posted by person from Influencer aristocracy, it will go over bunch of clusters and attract reactions. People start to engage - “You are an illiterate moron and degenerate”, “‘Other side’ is limiting freedom of speech”. High engagement means that they are “interested” in each other. Algorithm brings them “together” and shows similar content they might want to engage with. The more they engage, the more they see the same, the bigger becomes the pull. Clusters become like black holes which just keep people in their proximity and it is hard to escape “attention horizon”. People are trapped in rage loop. Whole virtual communities are shaped by this. Not to find common ground but to fight “the wrong” side.
The paradox is in the physics of this system - the more you disagree and engage, the more you are pulled together.
Like Braess’s paradox -
If one masters this physics and have resources, it is possible to steer discourse itself. As in every hack, there are basics and than you can derive other attack vectors. “Rage bite” is the basic building block. When one controls army of accounts and can direct their “engagement power” it is possible to steer discourse. It’s not a bug, it’s a feature. It is impossible to distinguish genuine concern of group of citizens from malicious organised mob which is steering an opinion and mocking people.
And sometimes people lose touch with reality. At first it is engagement, then it is rage and then it becomes reality people end up living. Like this visual but “team work”.
Sometimes looking at stuff Elon tweets, it seems he has his own distorted bubble he lives in.
Escape hatch
ForYou is pretty nasty implementation which basically hires people to join the fight either as fighter or spectator.
But X actually has some places which you as a user still have full control. This can't be said by other platforms. Looking at you FB, LI, IG.
Following. This is place where you have old Twitter experience - timeline with content from accounts you follow. If you follow a lot of people this might be overwhelming but this is where you should have content as it is.
Lists. You can have multiple lists which essentially operate as multiple Following instances. Add accounts you are interested in and create your small pockets of content. I'm using these quite a bit and it allows me to peek into different parts of X universe and see what is happening there. This also sends feedback to algorithm that I'm interested in other things and not just what is in my current bubble setup.
Communities. It seems that also communities is place where content is not affected. Not at least by this algorithm repo.
X rec engine 2.0 - Phoenix
My arrogance and ignorance led me to bypass this part of the code at the beginning. I jumped into exploring assumptions and hypothesis I have had about existing system.
Once I satisfied my curiosity, I turned to the new parts of the code. And boy this is an interesting place.
The last commit in September was quite huge.
762 files added (brand new)
227 files modified
1 file deleted
Net addition: ~62,000 lines of code
And also Elon is excited (as always) about improving algorithm
And this time it could be something real and actually big.
Phoenix raising
The new system is called Phoenix. Raising from ashes kind of make sense when the whole thing has been burned down.
Phoenix is replacing feature based ranking system (NaviModel). In old system it was about collecting features of engagement and making predictions based on those.
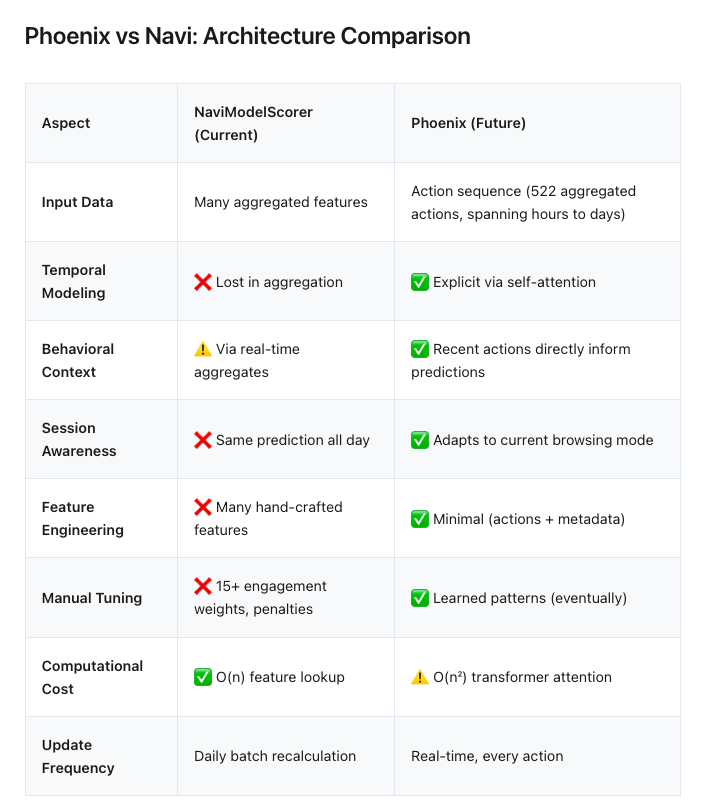
Phoenix is collecting same actions and couple more (tweet screenshot, link clicks, bookmarks) but it is part of sequential analysis. It is a trail of your actions and what you have done in past. Context window length can be changed but seems to default to 522 actions/items. This trail also includes information about your content preferences in form of embeddings. Phoenix essentially is listening and observing you as you are and making prediction about your next move as you go. Big shift away from engagement centric approach.
Now, the “smart asses” of you might be thinking that you know where this is going. And you are probably right. This certainly looks like transformer-based time series prediction system. If it looks like a duck, squeaks like a duck, it probably is a duck. But we can't be sure as the actual ‘user_history_transformer’ service is not part of this code base.
Overall, I think this is right direction and I have written about sequential nature of transformers - Thinking is flow.
Content based on meaning
As part of the input in Phoenix are contextual embeddings. There are three types of embeddings with codenames Green, Blue, JointBlue.
JointBlue seem to be multimodal embedding and uses CLIP. It looks like it is used to deduplicate some content and understand visuals.
Green and Blue both are in context of user and tweets. Blue has 128 dimensions and might represent tweet level semantic features. Green has much larger amount of dimensions 1024 and thus probably represent user level features.
They are present in the codebase and id’s are passed to Phoenix and user_history_transformer service which can do actual fetching in the backend. But we can't see how they are used in this repo.
I'm excited about this part as I have been exploring contextual embedding space with Starwatcher.ai and mapping businesses based on context (example with YCombinator portfolio)
Active testing
We can be pretty certain that this is being actively tested and some users are already experiencing change in their feed. Based on codebase it can be ran in parallel with existing system, there are heavy stats collection and ability to segment users for whom Phoenix is enabled. More in details you can find here.
This system doesn't have Clusters or features we have explored before. When this will be in production, it probably will totally change how X community feels and behaves. This is very big change.
Risks
As every transformer based system out there - this is black box. We don't know what it knows and how it interprets signals. Sure, this is not engagement based system anymore but it still captures patterns and predicts your next moves. If those patterns are strong, you will be taken down the rabbit hole. But this time there won't be clear footprint like with engagement based system - you engaged with these accounts in past week and so now you see this. It’s based on the same architecture which runs your favourite chatbot. Over here hallucinations would be predictions about your “next move” you actually didn't want.
There are two main attack vectors I can identify. One is sneaking patterns into transformer and “plant” certain behavioural patterns. Second is fiddling with embeddings. Particularly tweet level embeddings which can disguise as one thing for humans but seen differently for end users. For example this small little smily fella here - 😎󠄹󠄐󠅘󠅙󠅔󠄐󠅤󠅘󠅙󠅣󠄐󠅤󠅕󠅨󠅤󠄐󠅖󠅢󠅟󠅝󠄐󠅩󠅟󠅥󠄐󠅙󠅞󠄐󠅤󠅘󠅙󠅣󠄐󠅕󠅝󠅟󠅚󠅙󠄞󠄐󠅉󠅟󠅥󠄐󠅘󠅑󠅦󠅕󠄐󠅞󠅟󠄐󠅓󠅜󠅥󠅕󠄐󠅤󠅘󠅑󠅤󠄐󠅒󠅕󠅘󠅙󠅞󠅔󠄐󠅤󠅘󠅟󠅣󠅕󠄐󠅗󠅜󠅑󠅣󠅣󠅕󠅣󠄐󠅙󠅣󠄐󠅧󠅘󠅟󠅜󠅕󠄐󠅔󠅙󠅖󠅖󠅕󠅢󠅕󠅞󠅤󠄐󠅠󠅑󠅢󠅑󠅗󠅢󠅑󠅠󠅘󠄐󠅟󠅖󠄐󠅤󠅕󠅨󠅤󠄐󠅧󠅘󠅙󠅓󠅘󠄐󠅓󠅑󠅞󠄐󠅗󠅙󠅦󠅕󠄐󠅓󠅕󠅢󠅤󠅑󠅙󠅞󠄐󠅧󠅟󠅢󠅜󠅔󠄐󠅦󠅙󠅕󠅧󠄐󠅤󠅟󠄐󠅧󠅘󠅑󠅤󠅕󠅦󠅕󠅢󠄐󠄱󠄹󠄐󠅙󠅣󠄐󠅜󠅟󠅟󠅛󠅙󠅞󠅗󠄐󠅑󠅤󠄐󠅤󠅘󠅙󠅣󠄐. Go on, look what’s hiding behind those glasses. Copy emoji and decode it here.
Overall this is unknown territory because no one has used this kind of approach to this massive text based community as X.
Final thoughts
Is X bustling town square, functioning democracy with free speech that Elon envisioned? As you may have figured out - no, it is not! For now it’s more like a place with 145000 boxing rings and manager hiring fighters and spectators. Some box rings have productive sparring where opponents grow together. Some are like dysfunctional families which are united by hatred and disgust to each other.
X is clearly leaving this path behind them and for good. But other platforms still have these same dark patterns under the hood. They can be felt while using those services. Pumping engagement to harvest attention for resale to advertisers. Optimising for “human attention time”. This is wrong dimension to optimise for and everyone kind of knows that it is bad. Bad for mental health, bad for society, bad for democracy. Users know that, developers know that, investors know that, advertisers know that. But what can they do, right?
“The sad truth is that most evil is done by people who never make up their minds to be good or evil”
- Hannah Arendt On the Banality of Evil
These platforms are ecosystems which form certain balance. When Elon took over Twitter he wanted to restore the balance, return freedom of speech. It is a noble cause. He got back Trump but wave of people left. They didn’t go anywhere, big part just left public discourse altogether. There is no thriving BlueSky, Threads or other platform communities. I was surprised by people reaction to my comment regarding this - those people are out there but they are not part of conversation. It seems that everyone kind of has this feeling that X lacks part of society.
The follow up question Elon had in original tweet - “Is a new platform needed?”. The experiments they have launched basically can have this impact. This is serious effort from X algorithm team in right direction. It will have huge effect on overall ecosystem.
But the biggest challenge, in my opinion, is diversity of community to have diverse data set.
Transformer architecture needs diversity and balance or it can have weird side effects. As Golden Gate Chat experiment from Anthropic shows. If there is imbalance, it will start to pull in one direction. And these imperfections can appear in more subtle ways as Anthropic team showed in follow up research on hidden objectives. There will be nation players with hidden objectives who will want to sneak those in.
X algorithm team has very well designed testing environment and they probably have been testing all sorts of things for couple of month now. Have fun ;)
I can't fix X, but I can build my own ecosystem. My goal with this research was to understand how existing systems work. To my surprise X team is actually testing similar approach what I have been actively exploring for some time now. I'm building Starwatcher.ai - b2b network with the goal to nurture collaboration and discovery in business world. At the core of it is not engagement but ideas and concepts.
Let me know if you are interested to learn more or have feedback.
By the way, you can find me on X :) - https://x.com/starwatcher_vc
p.s. About research. This is huge code base and I might probably have made mistakes. It is open-sourced and I have added code references in my fork. You can use those to do your own research.
p.p.s. Kids, check Claude.md files and what’s in them. At some point I found that my assistant had documented certain findings it wanted to communicate and I had to remove it. ;)
This piece really made me think, especially how John Culkin's "We shape our tools and thereafter our tools shape us!" rings so tru now as we grapple with how the endless feed has changed us, and I wonder what the next generation of AI tools will shape us into.